In addition to code mobility, Mobility-RPC can be used as a general purpose RPC framework, providing the same (and more) functionality than RMI.
This page compares the performance of Mobility-RPC when used as a replacement for RMI.
The benchmark requires both Mobility-RPC and RMI to invoke a method in a remote JVM, supplying a collection of objects as a parameter. The method in the remote JVM simply repackages those objects into a new collection, and returns the new collection back to the client.
The relative performance of Mobility-RPC versus RMI is then measured both as the size of each request is increased (increasing the number of objects in the collection), and as the concurrency of requests is increased (increasing the number of threads invoking the method simultaneously).
These aspects are measured independently, such that when testing handling of different request sizes the number of threads is kept constant at one thread, and when testing different levels of concurrency the sizes of requests are kept constant at one object in the collection.
Results show that Mobility-RPC outperforms RMI by wide margins both under high levels of concurrency and with larger request sizes, and that the gap in performance between the two widens as stress is increased in either dimension.
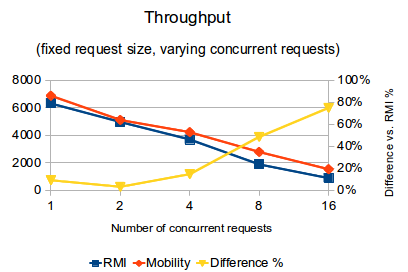
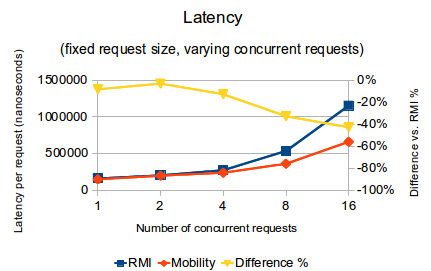
- When only one thread is making requests, Mobility-RPC achieves 9% higher throughput (requests per second) than RMI and its latency per request is 8% lower than RMI
- As concurrency is increased to 16 threads, the gap widens such that Mobility-RPC achieves 75% higher throughput than RMI, and its latency per request is 43% lower than RMI
 |  | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
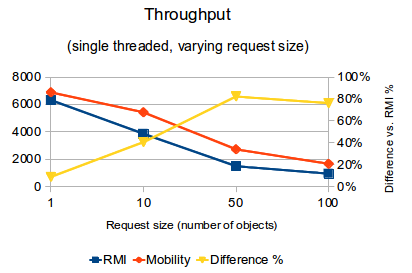
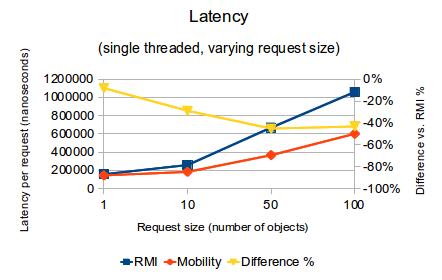
- When request size is small (one object in the collection), Mobility-RPC achieves 9% higher throughput (requests per second) than RMI and its latency per request is 8% lower than RMI
- As request size is increased to 100 objects in the collection, the gap widens such that Mobility-RPC achieves 76% higher throughput than RMI, and its latency per request is 43% lower than RMI
 |  | ||||||||||||||||||||||||||||||||||||||||||||||||
|
| ||||||||||||||||||||||||||||||||||||||||||||||||
The following is the method that both systems were required to invoke on the server. The method accepts a Collection of objects, and it repackages those objects into a new Collection (an ArrayList) which it then returns.
public class ServerBusinessLogic {
public static <T extends Comparable<T>> Collection<T> processRequest(Collection<T> collection) {
return new ArrayList<T>(collection);
}
}The following is the code to invoke the method across the network via Mobility-RPC. The design patterns for creating RMI server and client applications are well defined, so these are not shown but can be viewed in the benchmark source code here. 
// One-off initialisation...
MobilityController mobilityController = MobilityRPC.newController();
MobilitySession session = mobilityController.getSession(UUID.randomUUID());
ConnectionId connectionId = new ConnectionId("127.0.0.1", 5739);
final Collection<T> input = // logic to create an input collection for benchmark
Collection<T> result = session.execute(connectionId, ExecutionMode.RETURN_RESPONSE,
new Callable<Collection<T>>() {
public Collection<T> call() throws Exception {
return ServerBusinessLogic.processRequest(input);
}
}
);Note that Mobility-RPC only needs to be running on the remote machine. The ServerBusinessLogic class does not need to be deployed to the remote machine, it will be uploaded by the library automatically. It should also be noted, that if the class was deployed to the remote machine, as would be the case for RMI, it would not be transferred by the library.
Both client and server-side components of the benchmark were run on the same machine. This was intentional, because both RMI and Mobility systems have both client-side and server-side components, and this benchmark is an end-to-end evaluation.
The system used was a dual-core, hyperthreading-enabled Intel Core i7 1.8GHz Apple machine, with 4GB RAM, running Mac OS X 10.7.1, and the Apple-supplied Java HotSpot(TM) 64-Bit Server VM (build 20.1-b02-383, mixed mode) JVM. Only default JVM settings were used.
To simulate multiple concurrent requests, in the benchmark client multiple threads were started which executed the same benchmark code in parallel.
In each run of the benchmark, the benchmark logic was executed twice and the results from the first execution were discarded, to allow both code mobility and RMI client-side and server-side systems time to “warm up” (lazy-load any resources, initialize thread pools etc.). The RMI server and the Mobility server were restarted before each subsequent run.
In each run, threads performed 100,000 iterations (executing 100,000 remote invocations on the server). Average performance was subsequently calculated over the 100,000 iterations.
To test each system, a Collection of objects was created. Specifically Person objects, which contained fields for first name, last name, a list of two phone numbers, and fields for a personId, house number, street, city and country. Each Person object added to the collection was iteratively created to be unique.
Time taken client-side for the benchmark to create collections of Person objects was excluded.
The benchmark was then run with varying numbers of request threads and various request sizes. When testing varying numbers of threads, the request size was fixed at 1 for those sessions (1 Person object to be sent in the Collection to the server). Similarly when testing varying request sizes, the number of threads at was fixed at 1.
Full source code of the benchmark can be found here.